머신러닝으로 접근하는 문제들
Forecast
시간의 흐름에 따라 기록된 데이터를 이용하여 변수들 간의 인과관계를 분석하여 미래를 예측하는 영역
주 활동 영역은 날씨, 주식, 상품 판매량 예측 등
숫자가 존재하는 모든 영역에서 연구되고 구현되는 분야
대표적인 알고리즘: AR(I)MA, DeepAR
시간의 흐름에 따라 변하는 다양한 변수를 활용한 시계열 예측이 지속적으로 발전하고 있는 추세
타겟 변수와 상관관계가 높은 변수를 활용
시계열 예측에도 Regression, Classification의 응용이 사용됨
Recommendation
Netflix Prize를 통해 추천 연구 분야가 널리 알려짐
가장 간단한 나랑 비슷한 취향의 사람을 찾아주는 방법 Collaborative Filtering
가장 비슷한 컨텐츠를 찾아주는 방법 Content based Filtering (행과 열의 위치를 바꿔서 분석)
현실 데이터는 희소성 Sparsity 문제가 크기 때문에 알고리즘 적용이 어려움
Matrix Factorization과 Factorization Machine 사용
Anomaly Detection
공정 프로세스 관리, 금융 사기 거래 탐지에서 많이 사용되는 머신러닝 문제
현업에서 정의한 Normal을 벗어나는 데이터를 Abnormal라 정의
단순히 Outlier detection부터 Out-of-Distribution, One Class Classification (OCC)등 다양한 방법으로 접근
Image processing
Deep Learning 출현 이후 지속적으로 발전하여 현재는 사람 인지보다 높은 성능
Main Task는 1) Classification 2) Localization 3) Object Detection 4) Instance Segmentation
연구는 독립적으로 이루어지지만, 현업에서는 sub task와 혼합하여 사용
제조업에서는 Image Processing을 적용하여 양품/불량품 자동 판정 모델 이용
차량의 카메라 센서를 이요하여 운전자가 바라보는 방향의 이미지와 운전자가 볼 수 없는 영역의 이미지를 이용하여 Object detection으로 사물을 식별하고, Object classification을 통해 사람, 장애물, 차로 등을 식별
OCR (Optical Character Recognition) 을 활용하여 아날로그 → 디지털 전환에 편리성 제공 (신분증 사진에서 필요한 정보 자동 수집)
NLP
NLP (Natural Languaga Processing) 는 컴퓨터가 인간의 언어를 처리하는 모든 기술을 의미
대표적인 Task는 감성 분석, 대화생성 (챗봇), STT (Speech To Text)
제품 리뷰의 Negative 비율을 관리하여 상품 평판 관리
다양한 미디어 매체의 데이터에서 부정적 의견을 모니터링하여 회사에 대한 평한 관리
CS (Customer Service) 업무 중 반복적인 질문, 복잡도가 높지 않은 질문에 대한 자동 응대 (인건비 감소)
Data Cleaning 데이터를 쓸 수 있게 만들자
Missing Value
-실제 데이터에서는 N/A, Null 등의 이상값이 존재 → Missing value 처리
-Zero 비율이 0.95 이상인 경우 → 분석에 의미가 있는지 재확인 혹은 Drop
-독립변수 간 상관관계가 높은 경우 → 다중공선성 의심
Class Imbalance
-Class Imbalance 체크 → 비율이 0.9 이상인 경우, 샘플링 고려
-실제 데이터는 대부분 Imbalance 하기 때문에, Imbalance 데이터를 Drop 하는 것보다 밸런스를 맞출 수 있는 방법을 사용하는 경우가 많음
-한쪽을 줄이거나 늘리는 방법보다는 실제 데이터의 분포를 유지하면서 데이터의 밸런스를 맞출 수 있는 방법을 적용해야 함
Feature Engineering
인코딩
-우리 모두 알고 있듯이, 컴퓨터는 정보에 대한 개념이 없음
-문자도 숫자로 바꿔줘야 하고, 우리가 흔히 사용하는 카테고리의 경우도 모두 숫자로 바꿔줘야 함
ex) 알파벳 순서대로 숫자 index 할당(Label Encoding) / 등장하는 데이터의 사전을 만들고, 이진수와 유사하게 표현 (One-hot Encoding)
이산화
-연속형 변수들은 왜도가 높거나 정규분포가 아닐 가능성 높음
-데이터에 따라 변수의 값들을 단순한 몇 개의 그룹 (Bin) 으로 나누는게 효율적
-이산화를 적용하기 위해서는 변수에 결측치가 존재하지 않아야 함
-왜도가 작은 경우, |왜도| < 1 의 경우 Equal Width Binning 사용
-왜도가 큰 경우 |왜도| > 1 의 경우 Equal Frequency Binning 사용
Scaling
-확률에서의 연산은 곱셈 연산이 많기 때문에 값의 범위가 클 경우, 너무 값이 커져서 연산 결과가 발산하게 됨
-거기에 더불어서 연산속도도 느려지고 메모리를 많이 차지하게 됨
-다양한 문제가 있지만, 주된 목적은 연산 결과가 발산하는 것을 방지하기 위해 scaling을 함
-MinMaxScaler, MaxABS Scaler, Standard Scaler, Robust Scaler
변환 (Transforming)
-Linear regression 또는 Gaussian Naive Bayes 와 같은 ML 알고리즘들은 연속형 변수에 대해 정규 분포를 가정하는 경우가 많음
-정규분포가 아닌 변수들은 Power Transforming을 사용하여 정규분포 또는 정규분포에 가까운 데이터로 변환 가능
-변수에 0과 음수가 없는 경우: Box_Cox Transforming
-변수에 0과 음수가 포함된 경우: YeoJohnson Transforming
Extracing
-시계열 데이터에서 특징 변수 추출
→ 날짜형 데이터에서 년, 월, 일, 요일, 주말여부, 휴일여부 등을 추출
-구간별 평균, 합계, 기울기 등 구하기
ex) 7일간 평균, 합계, 기울기 추출을 통한 feature trend를 학습데이터에 추가
-Convolution으로 데이터를 원하는 형태로 추출하기
Feature Selection
-패턴이 지니고 있는 다수의 특징 중에서 당면한 결정을 하는데 필요 충분하다고 생각되는 소수의 특징을 골라 내는 것
-운영적 관점
1) 적재하는 데이터의 양이 적어지므로 시스템을 운영하는 비용이 감소
2) 적은 변수를 사용할 경우, 그렇지 않은 경우보다 시스템의 속도가 빨라짐
-통계적 관점
1) 데이터에 대한 해석력을 높여줌
2) 다중공성선의 문제에 대한 해결책으로 차원 축소를 이용할 수 있음
3) Robust 모델로 예측력의 향상을 기대할 수 있음 - Bias, Over Fitting 방지
상관 분석
- 두 변수가 얼마나 밀접하게 관련되어 있는지 알아보는 통계적 평가 방법
→ 상관계수가 매우 높을 때, 해당 독립변수가 종속변수에 대해 유의미하다고 판단함
-Pearson Correlation
→ 공분산을 활용하여 이를 표준화한 상관계수
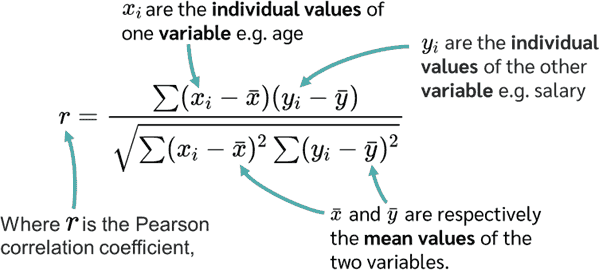
-Spearman Correlation
→ 값의 Scale은 무시하고, X와 Y의 순위 좌표로 전환하여 계산 (이상치에 대한 영향 감소)
Linear model
-전체 p-value가 일정 수준보다 작아질 때까지 p-value가 큰 변수를 제거한느 방법
→ p-value는 X값과 Y값이 우연히 발생할 확률을 의미 → 낮은 값일수록 우연일 확률 낮음
-모든 X에 대해 p-value를 계산하고 각 스텝마다 p-value가 가장 높은 X를 제거 (반복)
Feature importance
-예측에 가장 큰 영향을 주는 변수를 Permutation 하며 찾는 기법
(Feature 간 상관관계가 존재하는 경우에는 사용을 지양)
-Permutation Importance, SHAP 등이 사용됨
-SHAP (Shapley Additive exPlanation)
Game theory: 여러 주제가 서로 영향을 미치는 상황에서 어떤 의사결정이나 행동을 하는지에 대한 이론
SHAPLEY Value는 모든 가능한 조합에 대해서 하나의 Feature의 기여도를 종합적으로 합한 값
Data Sampling
Undersampling
-데이터 내 클래스 비율이 Imbalance할 경우, 타겟의 모수가 많은 쪽을 줄이는 기법
-Random, Near Miss, Tomek LInks, ENN 등
-Random Undersampling은 지정한 종속변수의 Category 중 비율이 적은 Category를 기준으로 비율이 높은 Category의 데이터를 Random한 방법으로 제거
-Near Miss Undersampling은 Near-Miss 알고리즘을 사용하여 데이터를 제거하는 방법
제거할 대상을 선정하기 위해 이웃한 근접 데이터 간의 거리를 계산하기 때문에 오래 걸림
-Tomek Links는 데이터의 중심 분포를 거의 유지하면서 분류 경계를 조정하기 때문에 제거되는 샘플이 한정적임 → Undersampling의 효과가 낮음
-ENN (Edited Nearest Neighbours)는 다수 클래스 데이터 중 가장 가까운 (Nearest Neighbours) k개의 데이터가 모두 다수 클래스가 아니면 삭제하는 방법 → 소수 클래스 주변의 다수 클래스 데이터는 삭제
Oversampling
-데이터 내 클래스 비율이 Imbalance할 경우, 타겟의 모수가 많은 쪽을 줄이는 기법 (Random, SMOTE)
-Random은 Undersampling과 반대로 비율이 낮은 데이터를 Random으로 복제하여 데이터의 양을 늘림
-SMOTE (Synthetic Minority Oversampling Technique)은 무작위로 선택한 데이터에 KNN을 수행, 수행한 X(KNN)와 X의 사이에 위치한 가상의 데이터를 생성
→ SMOTE는 비율이 낮은 데이터도 생성하지만 높은 데이터도 생성할 수 있음
Combination
-실전에서는 한가지 방법만 시도하지 않음
-SMOTEENN, SMOTETOMEK 등
-SMOTEENN = SMOTE(Over) + ENN(Under)
→ SMOTE를 통해 소수 클래스 데이터를 Oversampling하고 ENN을 통해 다수 클래스의 데이터를 Undersampling 하는 방법
-SMOTETOMEK
→ SMOTE를 통해 소수 클래스 데이터를 Oversampling 하고 TOMEK를 통해 다수 클래스의 데이터를 Undersampling 하는 방법 → TOMEK의 특성으로 인해 결정 경계가 뚜렷해짐
Supervised learning
-타겟 Y가 명확하게 존재하는 경우 사용하는 학습 방법
-현업에서 만날 수 있는 대다수의 문제가 supervised
-Regression, Classification, Deep learning
Unsupervised learning
-타겟 Y는 없고 독립변수 X만 있는 경우
-Topic Modeling, Clustering
데이터의 내재된 패턴을 찾거나 비슷한 속성을 가지고 있는 관측치들끼리 그룹화
Regression
회귀(Regression)이란 'go back to an earlier and worse condition'으로,
예전의 대표적인 상태로 돌아가는 특성에 기반한 분석을 의미
장점
-Model이 간단하기 때문에 모델의 학습시간이 짧음
-선형 데이터에 적합
-직관적 해석이 가능함
단점
-비선형 데이터에 부적합
-다차언의 데이터의 경우에는 결과의 신뢰도가 낮음
방법
Simple Linear Regression
Polynomial Regression
Logistic Regression
Classification
Regression이 데이터를 가장 잘 표현하는 함수를 찾는 방법이라면,
Classification은 데이터를 가장 잘 나눌 수 있는 최적의 분류 경계를 찾는 방법
SVM
Support Vector Machine은 Binary classification 문제에 좋은 성능을 보이는 알고리즘
2개 클래스의 데이터를 가장 잘 나눌 수 있는 경계를 찾는 알고리즘
경계선의 너비 (Margine)가 넓은 모델이 성능이 우수한 모델
차원의 저주
차원이 늘어나면 늘어날수록 연산이 오래걸리고, 원하는 퍼포먼스를 얻기 어려워진다
Binary classification VS Multiclass classification
-A가 아닌 나머지 / B가 아닌 나머지 / C가 아닌 나머지로 분류
→ 겹치는 것은 voting을 통해 (교집합) 횟수에 따라 클래스를 결정
-가중치를 A, B, C를 다르게 두어 계산
One class classification (OCC)
-공장이나 생산 쪽 분량에 관한 데이터가 적기 때문에 (ex 100만개 중 2-3개만 불량)
불량이 아닌 데이터만 가지고 학습을 수행하는 경우
Clustering
비슷한 특성을 가진 데이터들을 하나의 그룹으로 묶는 작업
특성의 유사도를 판단하는 기준: Distance, Connectivity, Distribution, Density
좋은 Clustering?
-같은 클러스터 내의 데이터는 서로 높은 유사도를 나타내야 함
-다른 클러스터 간의 데이터는 서로 낮은 유사도를 나타내야 함
방법들
DBSCAN: 'DB' (Density Base 밀도) 밀도 기준 클러스터링, 실무에서 많이 사용 ex) 실시간 위치에 따른 서비스 추천
K-means clustering: 베이스라인 잡을 때 (클러스터 할 수 있다 없다 볼 때)
Hierarchical clustering

Train / Validation / Test
어떻게 좋은 모델을 선택할까?
1. 전체 데이터를 Train 데이터와 Test 데이터로 나눔
→ Train 데이터와 Test 데이터는 겹치는 부분이 있으면 안됨
→ 둘은 가능한한 최대한 독립적인 관계를 갖는 것이 좋음
2. Train 데이터를 이용해서 다양한 모델을 생성
3. Test 데이터를 이용하여 생성된 모델을 검증
4. Test 데이터에서 가장 좋은 성능을 보인 모델을 선택
Training Set / Test Set randomly split
→ Model buile → Best model 선택
→ Test
Train 데이터로는 모델 만들 때는 좋았는데, Test 데이터에서는 좋지 않은 경우가 발생할 수 있음
Train / Test 성능
1. 적절한 Test 데이터의 크기?
→ 전체 데이터의 50~30% 정도 (정답 X)
2. 장점
→단순해서 직관적으로 이애할 수 있음
→구현하기 쉬움
3. 단점
→Test 데이터는 모델 생성에 사용되지 않음
→데이터가 무작위로 나눠짐
※ 데이터가 어떻게 나뉘냐에 따라 검증 결과가 많이 다름
해결 방안
→ Randomly Split 단계에서 Training Set / Validation Set / Test Set 으로 나누기
→ Validation Set Evaluation
→ Test
→ Model build
→ Best Model 선택
Validation 추가
-학습 과정에서 Unseen data에 대한 성능을 측정할 수 있음
-학습 과정에서 Overfitting에 대해 감지할 수 있음 → Easy Stop 가능
→ Validation Set에서 성능이 안좋으면 학습을 멈출 수 있음
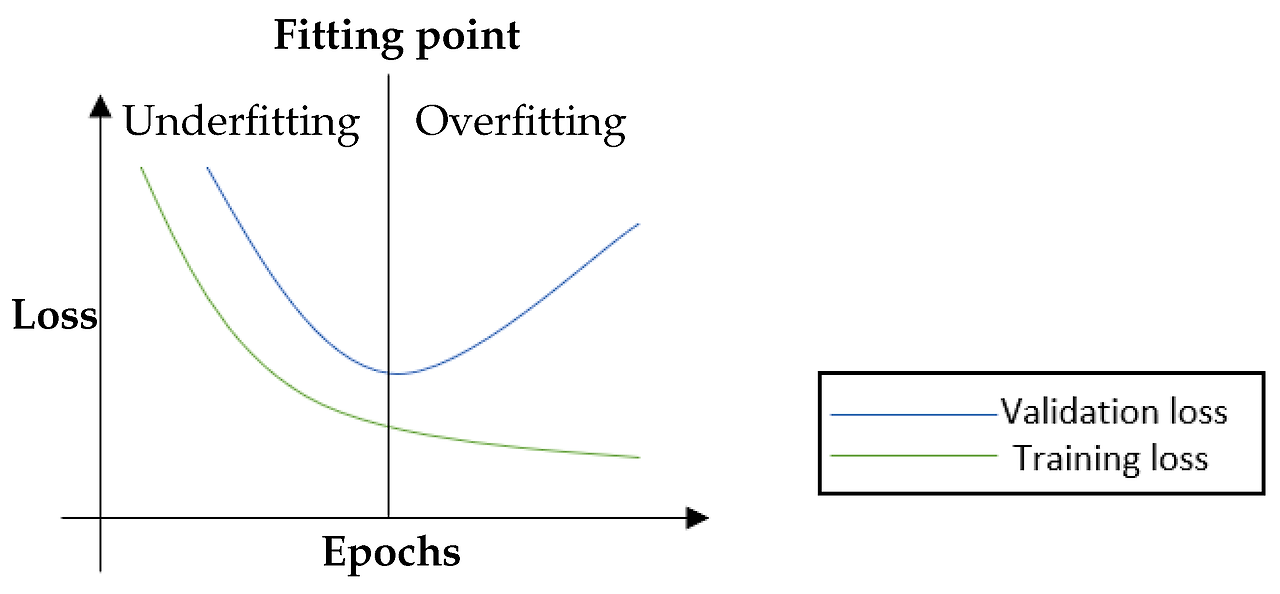
Cross Validation
-결과에 대한 분산을 줄이기 위해 사용하는 기법
→ K-fold Cross validation이 대표적으로 많이 사용됨
K-fold Cross validation
전체 데이터를 K개의 fold로 나눔
fold간 데이터는 서로 겹치지 않게 나눠야 함

타겟의 갯수에 루트를 씌우면 'K'값을 대략적으로 파악할 수 있음
다른 cross validation 기법
-StratifiedKFOld는 K fold Corss validation에서 Lable의 분포를 고려하지 않는 문제점을 보완한 Cross validation 기법
Class 별 Label 분포를 고려하여 Fold를 나눠서 Fold별 class 불균형을 해결
Over / Under Fitting
에러 0 (zero), 최선의 모델일까?
→ No
모델을 만들 때 '일반화된' 모델을 만들 것인지 '특화된' 모델을 만들 것인지에 관한 고민을 항상 해야 함
모델의 목적에 따라 결정
주어진 데이터를 정확하게 맞춰야 하는 Task (의료, 우주) vs Unknown 데이터를 최대한 정확하게 맞춰야 하는 Task
Under fitting → Over fitting
Step이 진행 될수록 성능 향상, 모델 복잡도 증가
계속 모델 복잡도가 증가하면,
→ 학습 데이터에 대한 성능은 계속 좋아짐
→ Unknown 데이터에 대한 성능은 계속 나빠짐
결국, 모델의 목적에 맞게 적절하게 선택
Model metrics
모델 평가 축도
-모델이 '잘' 학습되었는가를 확인할 수 있는 평가 수준이 필요
-공통적으로 공감할 수 있는 지표 필요
☆담당자들이 알 수 있는 지표인가?
일반적인 척도
● 일반적으로 많이 사용되는 모델 평가 척도 (분류)
-Accuracy: 분류의 전체적인 정확도를 확인 할 수 있는 지표
-Recall: 분류하고자 하는 클래스를 분류하였는지를 측정하는 지표
-Precision: 모델이 분류한 클래스가 제대로 분류하였는지를 측정하는 지표
-F1: Recall과 Precision의 조화 평균 (F1이 높으면 Recall과 Precision이 적절하게 높게 나왔다는 뜻)
● 일반적으로 많이 사용되는 모델 평가 척도 (회귀)
-MAE (Mean Average Error): 실제 값과 예측 값의 차이 평균 (평균의 이상값때문에 해석에 어려움이 있음)
-MAPE (Mean Average Percentile Error): 실제 값과 예측 값의 비율 차이의 평균
-MSE (Mean Squared Error): 실제 값과 예측 값의 차이를 제곱하고 평균
-RMSE (Root Mean Squared Error): MSE의 제곱근

특수한 척도
● 클래스가 명확히 나눠지지 않고 순위로 평가하는 경우 (추천)
Precision@k: 예측한 결과의 상위 K개와 실제 결과의 상위 K개의 매칭 정도
Recall@k: 예측한 결과 K개 중 실제 결과에서 나왔어야 하는 정도
● 겹치는 정도를 측정하기 위해 사용하는 척도 (이미지)
IoU (Intersection of Union)
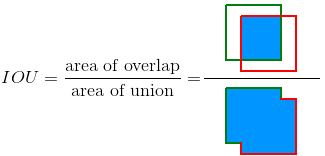
● 데이터 간의 거리를 측정하기 위해 사용하는 척도
Distance (Euclidean, Cosine, Manhattan)

Visualization
EDA (탐색적 데이터 분석) 결과 → 시각화
중간 결과 → 시각화
시작과 끝
모델링 후 성능 모니터링 대시보드 구성
→ 분석가에게 시각화는 뗄래야 뗼 수 없는 도구
성능보다는 성과가 더 중요
내가 만든 모델을 '성과'와 연결시키는 사람이 좋은 분석가
ex) 내가 추천한 아이템들은 하루에 몇 개씩 팔리고 있어 (O)
ex) 나는 논문을 한달에 30편씩 읽고 구현해봤어 (X)
Chart 데이터 기반 vs Graph 수식 기반
차트 종류
Line chart : Time series 데이터 Seasonality 확인
Bar chart (histogram) : 데이터의 분포 확인
Pie chart (비율) : 타겟 비율 확인
Box plot : 변수 별 최대값, 최소값, 사분위수 비교
HeatMap (scale, correlation) : 2개의 카테고리 값에 대한 값 변화 모니터링
똑같은 결과를 갖고 와도 시각화를 잘하는 분석가가 제대로 인정을 받는다
'[데이터분석] > Python | AI | 머신러닝' 카테고리의 다른 글
| Python을 활용한 프로그래밍 확률통계_Part 2 (0) | 2024.07.29 |
|---|---|
| 실무 중심의 데이터 분석 방법 Part.3 (0) | 2024.07.28 |
| Python을 활용한 프로그래밍 확률통계_Part 1 (1) | 2024.07.22 |
| 실무 중심의 데이터 분석 방법 Part.1 (0) | 2024.07.16 |
| [DACON] 고객 대출등급 분류 기본 학습 (0) | 2024.02.27 |